Notes from Agent Engineering Day 2, on the talk Self-Improvement of Context, Harness, and Model Weights through Reflective Optimization.
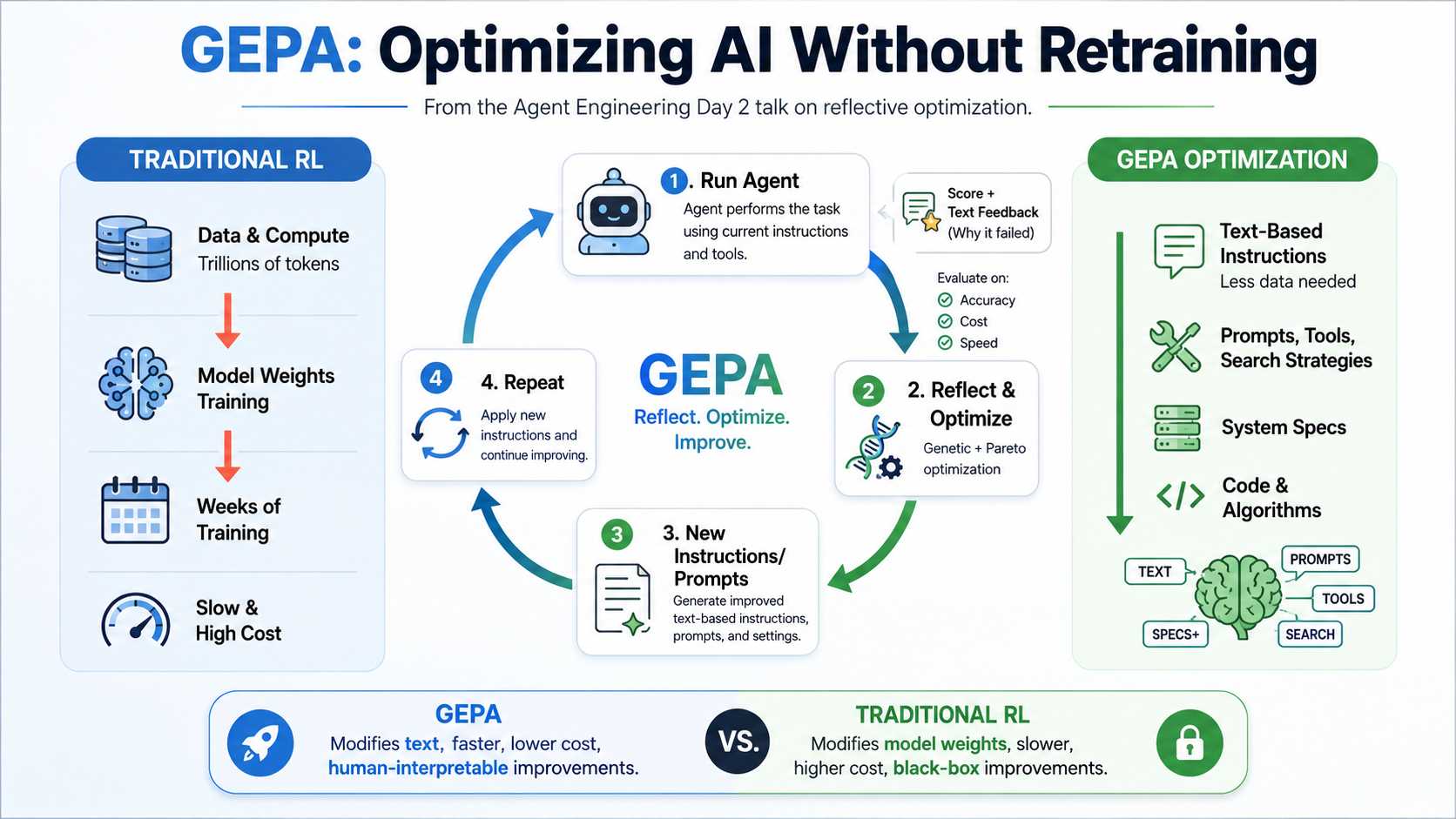
There’s a reflex in AI engineering right now that goes: model underperforming? Fine-tune it. Still underperforming? More rollouts. Reinforcement learning methods like GRPO can need thousands of them to learn a single new task — which is a fine plan if you happen to have a GPU cluster and a few idle weeks lying around. Most teams have neither.
The talk’s opening line reframed the whole problem:
We do not always need to retrain a model to make an AI system better.
That’s where GEPA comes in.
What is GEPA?
GEPA is a reflective prompt optimizer. Instead of only improving the model’s weights, it improves the text around the model — prompts, system instructions, tool-use rules, agent harnesses, search strategies, evaluation instructions, even the architecture descriptions that tell an agent how to behave.
The talk framed this as reinforcement learning, just conducted in text space instead of weight space. Ordinary RL hands the system a number:
This run got 7 out of 10.
GEPA hands it a paragraph:
score + text feedback
That feedback says why: the agent used the wrong tool, the search query was too broad, the answer missed part of the question, the prompt never told the agent how to recover when something failed. Knowing you failed is not that informative. Knowing how you failed is where the improvement actually comes from.
Genetic optimization, in plain English
One piece of GEPA is described as genetic, which sounds like it belongs in a biology lecture rather than a prompt-engineering one, but the idea is not exotic.
Start with a handful of prompt candidates. Some are bad, some are mediocre, one or two are good. Run them against test cases, keep the strong ones, mutate and combine them, test again. Repeat until the population gets better.
In plain English:
Genetic optimization is structured trial and error, guided by feedback.
The “structured” part matters — GEPA isn’t throwing darts. It uses the reflective feedback from failed runs to write better candidates. A first-draft prompt might say:
Given the question and summary, produce a search query.
After a few rounds of reflection, GEPA tightens it into something a lot more specific:
You are generating a second-hop search query. The first-hop documents already answered part of the question. Your job is to identify what information is still missing and generate a query to retrieve that missing information. Do not simply repeat the original question.
That’s not a longer prompt for the sake of being longer. It’s a better spec.
Pareto optimization, in plain English
GEPA also runs Pareto — multi-objective — optimization, because a single score hides too much. Real systems trade off accuracy against cost, speed against reliability, generality against tool-use quality. A prompt that nails one task can flop on the next; a longer, more careful prompt might raise accuracy while quietly tanking latency and your token bill.
In plain English:
A Pareto-optimal option is one where you can’t improve one thing without making something else worse.
So instead of chasing “what is the single best prompt,” GEPA asks “which candidates hold up strongest across different goals and tradeoffs.” It can find test-case-specific winners first and combine the lessons later — a genuinely useful engineering habit: don’t average everything into mush before you understand what’s actually working and where.
GEPA vs GRPO
One slide put GEPA head to head with GRPO on multi-hop question answering. The claim: GEPA outperformed GRPO by up to 20% while using up to 35x fewer rollouts, across tasks spanning more than five domains.
The scoreboard number is nice, but the real point is what it implies — GEPA improves the context and harness around the model, not the weights themselves. Which means it works even when the model is a black box you can query but never fine-tune. Most of us are living in exactly that world.
optimize_anything
The talk also introduced optimize_anything, a unified API for reflective optimization, built on the premise that if a thing can be represented as text, it can potentially be optimized. Prompts, agent architectures, code, CUDA kernels, scheduling policies, algorithm descriptions — all fair game.
The general pattern underneath all of it:
Reflect on failures, diagnose what went wrong, propose better text-encoded solutions, and test again.
Results were shown across ARC-AGI, CUDA kernel generation, and cloud scheduling policy discovery. Different domains, same trick: use language as the medium for improvement.
Fast-Slow Training
The talk closed with Fast-Slow Training (FST), which pairs two kinds of learning:
- Slow weights — the model’s actual parameters, updated through reinforcement learning.
- Fast weights — textual context, prompts, and instructions, updated through GEPA.
The intuition: let the text layer absorb the fast-changing, task-specific details, so the model’s parameter updates are free to learn deeper, more general reasoning instead of memorizing every task’s particular quirks.
In plain English:
Let prompts and context handle the fast-changing details. Let model weights learn the deeper patterns.
The pitch is better sample efficiency, less model drift, and more plasticity preserved for continual learning down the line.
Why this matters for agent engineering
Picking the best model is maybe 20% of building a good agent. The rest is the system around it: what instructions it gets, what tools it has, how it decides which one to call, how it handles a failed call, how it searches, how it remembers, how it grades its own output, how it retries, how it formats the final answer.
Almost all of that is text. GEPA’s contribution is treating that text as an optimization surface instead of a one-off artifact some engineer typed once and never revisited — prompts as candidates to be tested, improved, and evolved, not tablets carried down from the mountain.
The practical takeaway
Do not assume the only way to improve an AI system is to retrain the model.
For most teams, the better first move is improving the text layer: better prompts, better system instructions, better tool descriptions, better agent harnesses, better failure feedback, better evaluation loops.
A practical GEPA-style workflow:
- Run the agent on real tasks.
- Collect failures and trajectories.
- Add text feedback explaining what went wrong.
- Generate improved prompts or instructions.
- Test the new versions.
- Keep the candidates that perform well across tradeoffs.
- Repeat.
That’s the part worth carrying home from this talk. GEPA reframes agent improvement as an ordinary engineering loop — observe failures, diagnose them, improve the spec, test again — which, for most teams, beats reaching for fine-tuning or RL as the first move.