Notes from AI Engineer SF, on Matt Pocock’s talk Building Great Agent Skills: The Missing Manual.
Every developer I know is sitting on a graveyard of .md files. A security-review.md copied from a coworker’s dotfiles. A slash command someone wrote at 11pm during an incident and never opened again. Three “code review” skills that all do the same thing, none of which you remember writing. Nobody sets out to collect these — they just accumulate, the way tabs do.
Matt Pocock has a name for this: Skill Hell.
Every developer now has dozens of agent skills — repos, IDE configs, someone else’s dotfiles, half-understood. Without a rubric for what makes one good, they’re just prompt clutter with better branding.
The idea that stuck: a good skill isn’t a longer prompt. It’s a small operating procedure for an agent — when to show up, what order to do things, what to read first, and what to ignore.
Below is the framework, with a security code review skill as the running example, because it’s the one I keep rewriting badly.
(And — happy Independence Day, America. Fitting timing to write about declaring independence from bloated skill files.)
Useful links:
- Building Great Agent Skills: The Missing Manual
- Matt Pocock’s writing-great-skills repo
- Ralph Code reference
The simple version
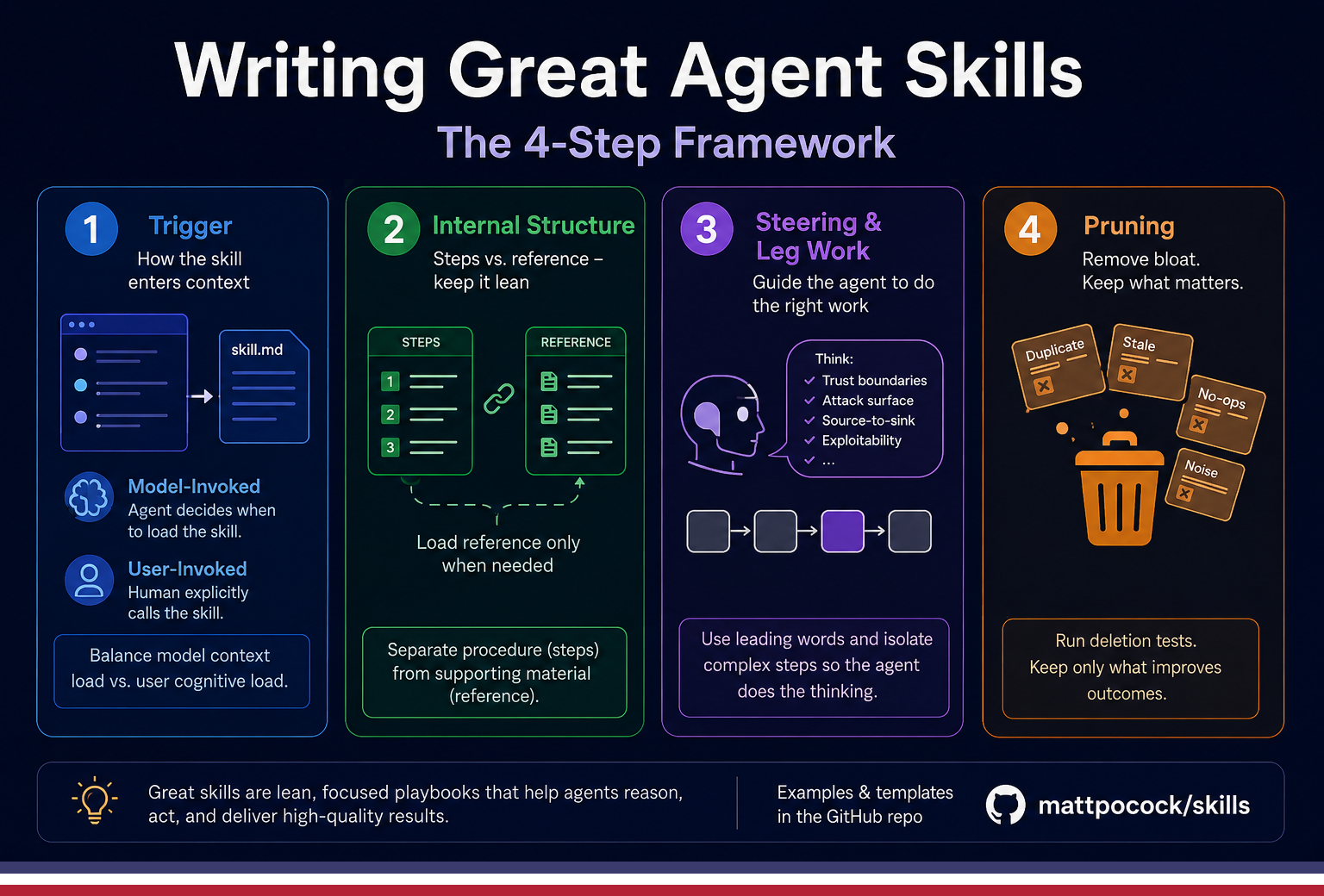
A skill should answer four questions:
- Trigger — how does the agent know to use it?
- Structure — what’s the workflow, and what’s just reference material?
- Steering — how do we force the hard thinking instead of the vibes-based answer?
- Pruning — what can we delete?
That’s the whole framework. Everything else is commentary.
1. Trigger: how the skill enters context
Two ways an agent finds out a skill exists.
Model-invoked: the agent reads a short description and decides whether to load the skill. Good when the task gives enough signal — “review this PR for security issues” should obviously reach for the security skill. Cost: more skills means more descriptions to skim before doing anything. A vague one (“use this for code quality”) is noise, like a coworker who replies “sounds good” to everything.
User-invoked: a human calls it explicitly, usually via a slash command. Cleaner context, but now you have to remember the skill exists and use it at the right moment — exactly the kind of thing that was the problem in the first place.
Mix them. Model-invoked for the obvious stuff (security review, test writing, PR review, bug triage). User-invoked for the deliberate stuff (release prep, migrations, architecture review, postmortems).
Keep the trigger narrow. “Use this for code quality” could mean anything. “Use this for security review of source code or PRs” tells the agent exactly when to show up.
2. Structure: steps vs. reference
Separate steps — the ordered procedure — from reference: checklists, examples, templates, background.
One giant skill.md that mixes both means the agent carries too much context on every invocation, and the actual workflow gets buried under three paragraphs of OWASP trivia nobody asked for right now.
Keep the main file lean; push longer checklists into their own files:
skills/
security-code-review/
skill.md
references/
vulnerability-checklist.md
finding-format.md
The blog post explains the idea. The repo holds the implementation. Nobody needs a 4,000-word skill.md any more than a 4,000-word Slack message.
3. Steering: make the agent do the hard work
Agents rush — it’s their one universal personality trait. In security review that’s dangerous: a shallow pass is worse than none, because it hands you false confidence with a bow on it. Grep for password, token, eval, ship three generic bullets, call it a day. Congratulations, you built an expensive linter.
Force the legwork first. The agent should read the relevant files, find related call sites, identify user-controlled input and trust boundaries, find sensitive operations, trace auth checks, and separate real findings from hardening suggestions.
Word choice matters more than expected here. Some terms just pull a model into the right frame:
threat model · trust boundary · attack surface · source-to-sink · exploitability · blast radius · false positive
Instead of “look carefully through the code and try to understand whether a user could do something bad,” say:
Build a brief threat model. Identify trust boundaries, attacker-controlled inputs, sensitive operations, and plausible exploit paths.
Same intent, half the words, and it actually points somewhere specific.
4. Pruning: delete the bloat
Skills rot quietly. A reminder here, an exception for that one edge case from March, a “just in case” clause. Six months later the skill file reads like a lease agreement, and is about as fun.
Prune aggressively: delete anything that doesn’t change behavior, anything duplicated, anything stale, anything that just restates what the model would do anyway.
This line looks like an instruction but is dead weight:
Provide detailed feedback on security code quality.
It’s a mission statement in a trench coat. Compare:
Only report findings grounded in inspected code. Each finding must include evidence, impact, and a suggested fix.
That changes the output. The test: delete the line — if the agent doesn’t get worse, it stays deleted.
Example: security code review skill
Here’s a rough first draft next to the tightened version — full files in this gist.
The draft’s description is broad enough to fire on almost anything, its checklist is two bullets doing the job of a whole security discipline, and its “workflow” names tools (Read, Grep, Glob) instead of reasoning — which hammer to pick up, never what to build.
The tightened version narrows the trigger, replaces “checklist” with an actual threat-modeling workflow, and adds explicit output rules (grouped findings, evidence required, “no high-confidence findings” as a valid answer). The detailed vulnerability checklist and finding-format spec move to reference files in the repo — the skill stays short, the rigor lives one directory over, pulled in only when needed.
Where Ralph Code fits
Ralph Code treats an agent less like a chatbot and more like a worker running a loop — and once you’re in loop-land, skill quality stops being a nice-to-have and starts being load-bearing.
A vague skill in a one-off chat is mildly annoying. A vague skill inside a loop can burn hours before anyone notices the agent’s been reviewing the wrong trust boundary since iteration three.
Looping agents need skills that are narrow, repeatable, easy to re-enter mid-loop, explicit about stopping conditions, and resistant to context drift — able to survive being read by an agent with no memory of how it felt the first time.
My takeaway
The best skills are lean, focused playbooks that tell an agent what to do, when, and how to produce something useful — then get out of the way.
Don’t write skills as advice. Write them as workflows.
Narrow the trigger. Keep the main file small. Move reference material to the repo. Use strong steering words. Force the legwork. Prune anything that doesn’t change the output.
A good skill should feel almost boring — predictable, auditable, the kind of thing you forget is clever because it just works. That’s the exit door out of Skill Hell. No renovation required, just fewer files, and the ones that remain earning their place.